Buffer Overflow Definition
When a system writes more data to a buffer than it can hold, a buffer overflow or buffer overrun occurs. A lack of proper validation causes this software vulnerability or bug, allowing data to be written out of bounds. This results in excess or lost data, and writes to the adjacent memory—overwriting whatever was stored there before, and triggering unpredictable effects.
A buffer overflow bug leaves a system vulnerable to attackers who can exploit it by injecting specifically tailored code. This kind of malicious code causes issues of buffer overflow in network security and places executable code in memory regions adjacent to the overflow. That latter code allows the attacker to run other programs or gain administrator access.
What is Buffer Overflow?
A buffer is a sequential memory allocation or region that might hold anything from integer arrays to character strings. The purpose of the buffer area is to hold program or application data while it is being moved from one program to another, or between sections of a program.
A buffer overflow happens when a program either tries to place data in a memory area past the buffer, or attempts to put more data in a buffer than it can hold. Writing data beyond an allocated memory block’s bounds can crash the program, corrupt data, or allow an attacker to execute malicious code.
Malformed input data—inputs that are the wrong size by design—may trigger overflows. This is possible because in many cases, designers assume all inputs will be smaller than a threshold size and create the buffer to fit that size. In these situations, some anomalous transactions can write past the edge of the buffer by producing more data.
Buffer overflows are among the most serious software weaknesses that attackers can exploit. This is because detecting and repairing buffer overflows is difficult, particularly when the software is very complicated. Sometimes buffer overrun bug fixes themselves are error-prone and complex. And even in cases where software has been fixed many times, many buffer overflow security risks may remain.
What is Buffer Overflow Attack?
Although most developers are familiar with buffer overflow attacks and they are among the most common software security vulnerabilities, they remain common against both newly-developed and legacy applications. This is partly because there are many ways to exploit a buffer overflow vulnerability, and partly because there are many ways to prevent buffer overflow attacks that are prone to errors.
The memory allocation and layout of many systems is well-defined, and that clear organization is easy to exploit. Buffers are one such common feature in operating system (OS) code. Overwriting known areas by causing an overflow can allow an attacker to seize privileges or replace executable code with malicious code.
For example, as early as 1988, the Morris worm used buffer overrun attack techniques. More recent examples include buffer overrun attacks against gaming communities like Steam that result in “outgoing reliable buffer overflow” error messages for users.
The C and C++ programming languages are often associated with understanding buffer overflows for several reasons. They lack built-in protection against accessing data anywhere in memory space, let alone overwriting data or source code. They also fail to automatically check whether data written to an array such as a buffer is within its bounds.
Bounds checking is possible with C and C++, but it demands additional processing time and code to prevent buffer overflows. Safer operating systems deploy a range of strategies in buffer overflow mitigation, such as space layout randomization, or intentionally creating space between destination buffers and writing actions called canaries or stack canaries into them for more effective monitoring of the issue.
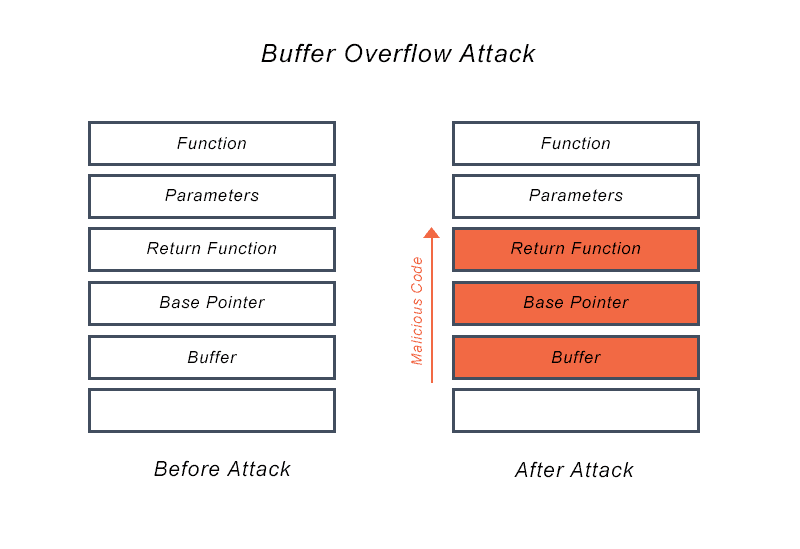
In a classic example, the attacker sends the program data. The program stores the data in an undersized stack buffer, causing the call stack data to be overwritten. Then, when the function returns, the data setsthe return pointer value and transfers control to the attacker’s malicious code.
This kind of stack buffer overflow is common among some development communities and on certain platforms. However, there are other varieties of exploits, such as off-by-one error, heap buffer overflow, and the similar format string attack.
See more on the types of exploit tactics below.
Buffer Overflow Examples
Most buffer overflow attack examples exploit vulnerabilities that are the result of programmer assumptions. Buffer overflow exploitation tactics are often based on mistaken assumptions about what data is and how large pieces of data are, combined with manipulation of system memory locations.
Usually, code with buffer overflow vulnerabilities:
- Depends upon data properties that are enforced outside of the code’s immediate scope
- Relies on external data such as user input to control its behavior
- Is too complex to allow programmers to predict its behavior accurately
Taking a closer look at the most common types of buffer overrun attacks:
Stack Buffer Overflow
The stack is like a place in the operating system’s memory for executing functions, bookkeeping, and local variables. The system reserves a block atop the stack when a function is called, and when it returns, that block is reserved for use again the next time a function is called.
Stack buffer overflow, also called stack-based exploitation, allows attackers to manipulate a system in multiple ways:
- Overwriting a local variable close to the stack’s vulnerable buffer to change program behavior
- Overwriting the stack frame return address to resume execution after the function returns, usually at a user-input filled buffer specified by the attacker in place of a return address
- Overwriting and then executing an exception handler or function return
- Overwriting a local pointer or variable of a different stack frame to be used by the function on that frame later
Ensuring the user-supplied data address is unpredictable makes exploitation of stack buffer overflow weakness and remote code execution more difficult. To get around this security measure, some attackers engage in trampolining, a technique that allows them to compute the location of their shellcode relative to a pointer they identify near the vulnerable stack buffer. Then, they can exploit instructions already in the memory to branch execution into the shellcode.
Heap Buffer Overflow
The heap is system memory designated for dynamic allocation. It differs from stack memory in that there is no last in first out (LIFO) pattern to how blocks are allocated in the heap. In the heap, you can allocate or free a block dynamically at any time—meaning tracking which parts are free or in use at any time is far more complex.
Heap-based exploitation exploits the heap data region of system memory in different ways.
Typically, the system allocates heap memory, which generally includes program data, dynamically by the application at run-time. An attacker aims to corrupt this data, causing the application to overwrite linked list pointers and other internal structures.
How to Prevent Buffer Overflow
There are buffer overflow prevention best practices to follow that will protect your system:
Assess buffer overflow vulnerability. First, determine if you are vulnerable. Stay current with the latest bug reports for all libraries and server products. Review all custom application software code that accepts user input via HTTP request to ensure it can handle unusually large inputs properly. This is critical to finding buffer overflows.
Stay current. Protect your system infrastructure by updating with bug reports and applying patches. Use a buffer overflow scanner to monitor your sites and applications for security risks. Next, consider which additional buffer overflow attack prevention tactics—each with benefits and tradeoffs—might work for your system and organization.
Language choice. A reliable buffer overflow solution is starting at the language level by avoiding vulnerable programming languages. However, this is no solution for legacy code, and business, technical, and other parameters often demand the use of a vulnerable language. For example, in part because they are not strongly typed and allow direct access to memory, C/C++ are vulnerable to the buffer overflow attack in network security. However, they remain popular programming languages.
C itself lacks built-in protection against buffer overrun because it does not check whether data written to a buffer is within its bounds. C++ behaves the same way without an explicit bounds check, although there are ways of buffering data safely in the standard C++ libraries, and containers that can check bounds optionally in C++’s Standard Template Library (STL)—if the programmer demands the bounds checks while accessing data explicitly.
Examples of strongly typed languages that do not allow direct memory access include COBOL, Java, and Python.
Some programming languages provide compile-time checking or runtime checking. These features can raise an exception or issue a warning under conditions that might cause C or C++ to trigger the program to crash. These languages include Ada, Cyclone, D, Eiffel, Lisp, Modula-2, Ocaml, Rust, and Smalltalk.
Most interpreted languages will protect the system by signaling well-defined error conditions such as read, serial, and ring buffer overflow for some system configurations.
Safe libraries. Use of safe libraries is another tactic in preventing buffer overflow. Standard library functions for the C and C++ languages expose your system to overflows because they are not bounds checked. Well-tested and written libraries centralize buffer management and perform it automatically, including bounds checking.
Arrays and strings are the two main types of data building blocks vulnerable to buffer overflows. Safer libraries therefore focus on these data types to prevent attacks. Frequently seen examples of functions to avoid are strcpy(), scanf(), and gets().
Buffer overflow solutions. These solutions detect the most common attacks by ensuring that the stack remains unaltered after a function returns. When a buffer overflow tool detects an alteration, it exits the program with a segmentation fault.
Dividing the stack. Dividing the stack into sections for data and function may also afford stronger stack protection. This is an incomplete solution to buffer overflows, however, since it protects the return address but may allow other sensitive data to be overwritten.
Pointer protection. Pointer protection is another aspect of buffer overflow prevention. Buffer overruns manipulate pointers, including addresses stored in the system. Adding code to these addresses protects these pointers by making it more difficult to reliably manipulate them.
Executable space protection. By protecting executable space, the system causes an exception should any attacker try to execute code that they insert into either the heap or the stack. In this way, executable space protection or data execution prevention doesn’t defeat the original vulnerabilities, but instead prevents execution of buffer overflow code once it is present. This also means it remains vulnerable to attacks that don’t rely on execution.
Even when attackers cannot execute arbitrary code, a buffer overflow often causes a crash. This then leads to a denial of service (DoS) that impacts application and process availability.
Address space layout randomization (ASLR). Address space layout randomization arranges important data areas randomly in the address space of a process. This type of virtual memory address randomization locates variables and functions to make buffer overflow exploitation more difficult, though still possible. This approach also stops internet worms by forcing attackers to tailor their exploitation attempts to each individual system.
Deep packet inspection (DPI) or packet scanning. This technique detects elementary, remote attempts to exploit buffer overflows at the network perimeter. The technique blocks NOP-sleds, long series of No-Operation instructions, and packets which have the signatures of known attacks using attack heuristics and attack signatures.
However, DPI or packet scanning is a basic and less effective method that can only work against known attacks. This technique is also vulnerable to encoding.
Buffer overflow testing tools. These tools vary, but their general goal is to detect buffer overflows, identify their causes, and patch those weaknesses. Edge case testing, fuzzing, and static analysis are all methods of automated buffer overflow testing.
Does Avi offer Overflow Protection?
The Avi application delivery platform serves as a gateway to your application, providing an out-of-the-box security solution for buffer overflow attacks. Avi prevents illegal requests from reaching your applications, blocking them from triggering a buffer overflow state. The platform also offers multi-layered application and website protection.
Avi Network’s Web Application Firewall (WAF) delivers high-performance web application security. WAF uses the Common Vulnerabilities and Exposures (CVE) catalog of known threats. This catalog is maintained by the Department of Homeland Security aiming to standardize the definition of exploits to simplify response for administrators. Exploits which take advantage of buffer overflow vulnerabilities are included in the CVE and prevented by Avi’s WAF.
For more on the actual implementation of load balancing, security applications and web application firewalls check out our Application Delivery How-To Videos.